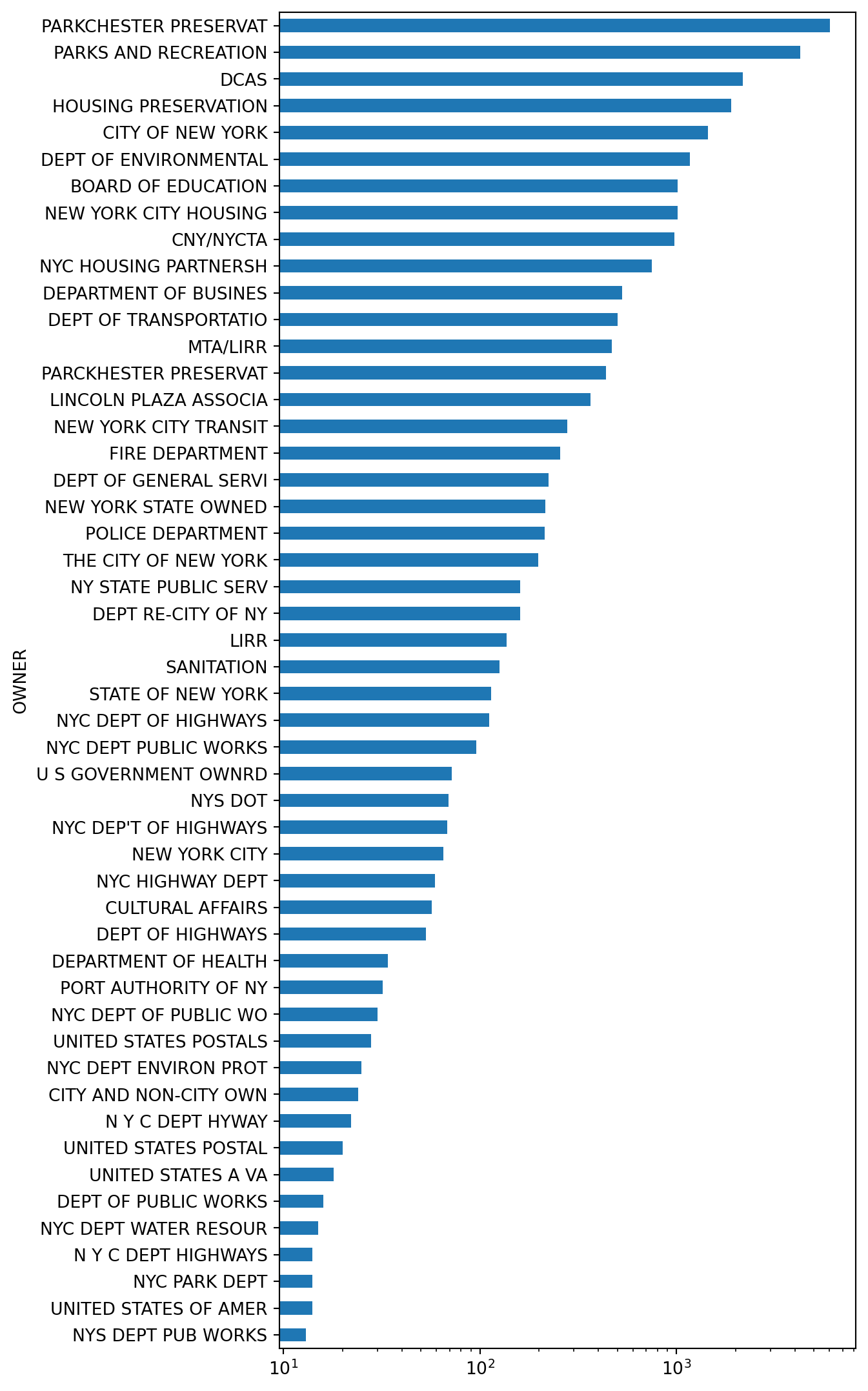
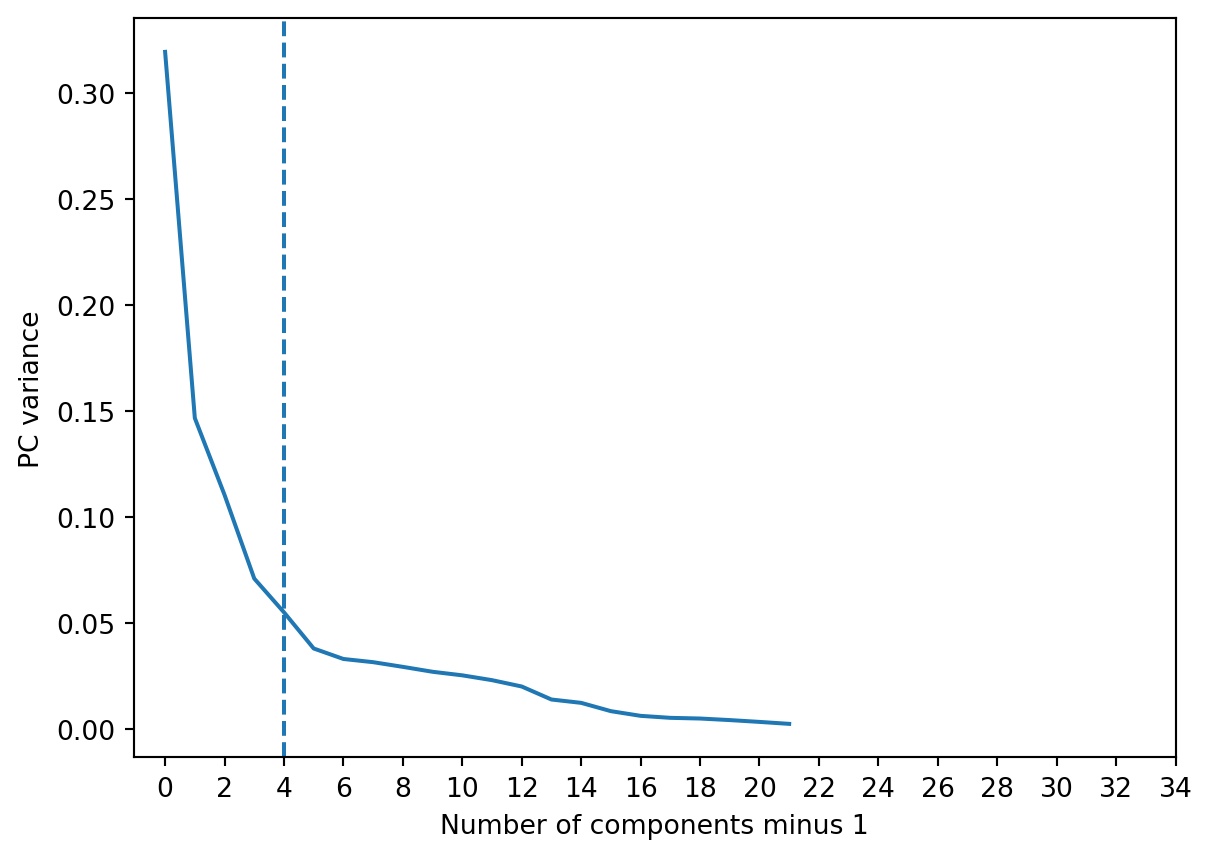
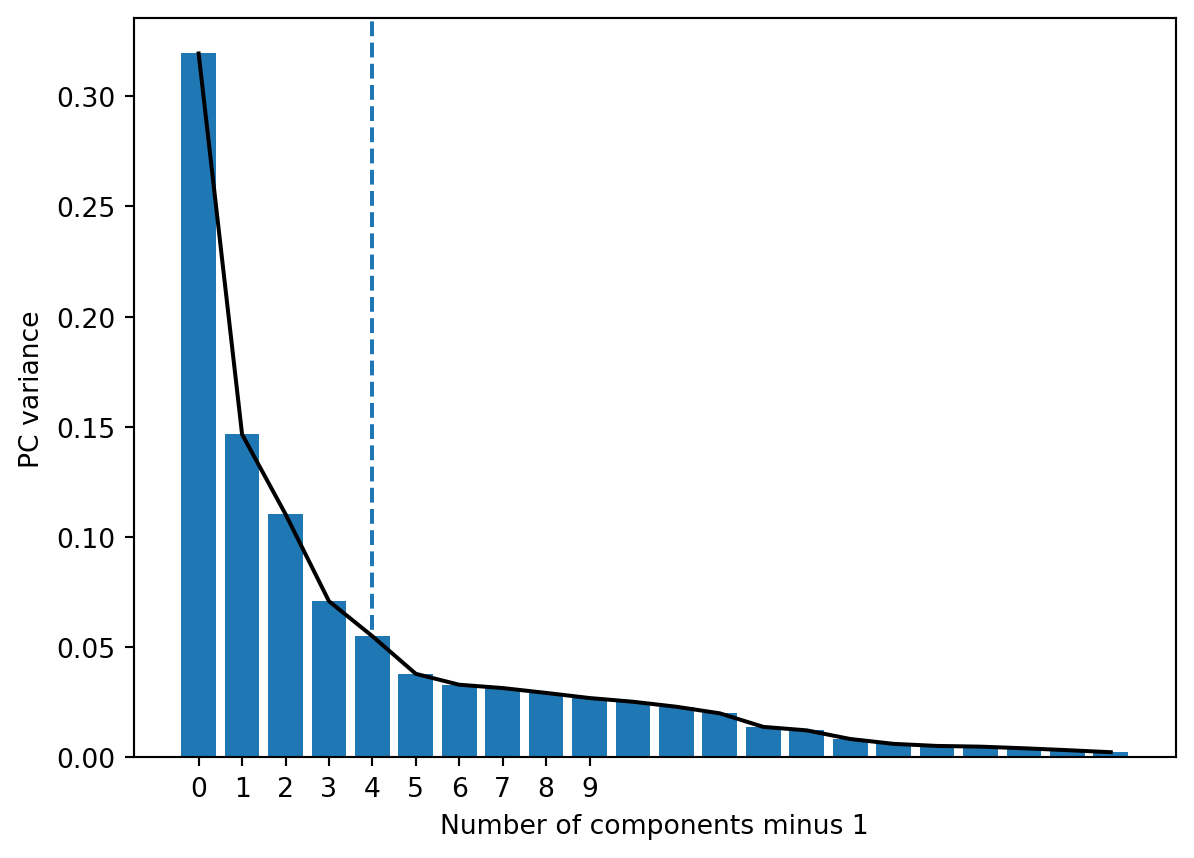
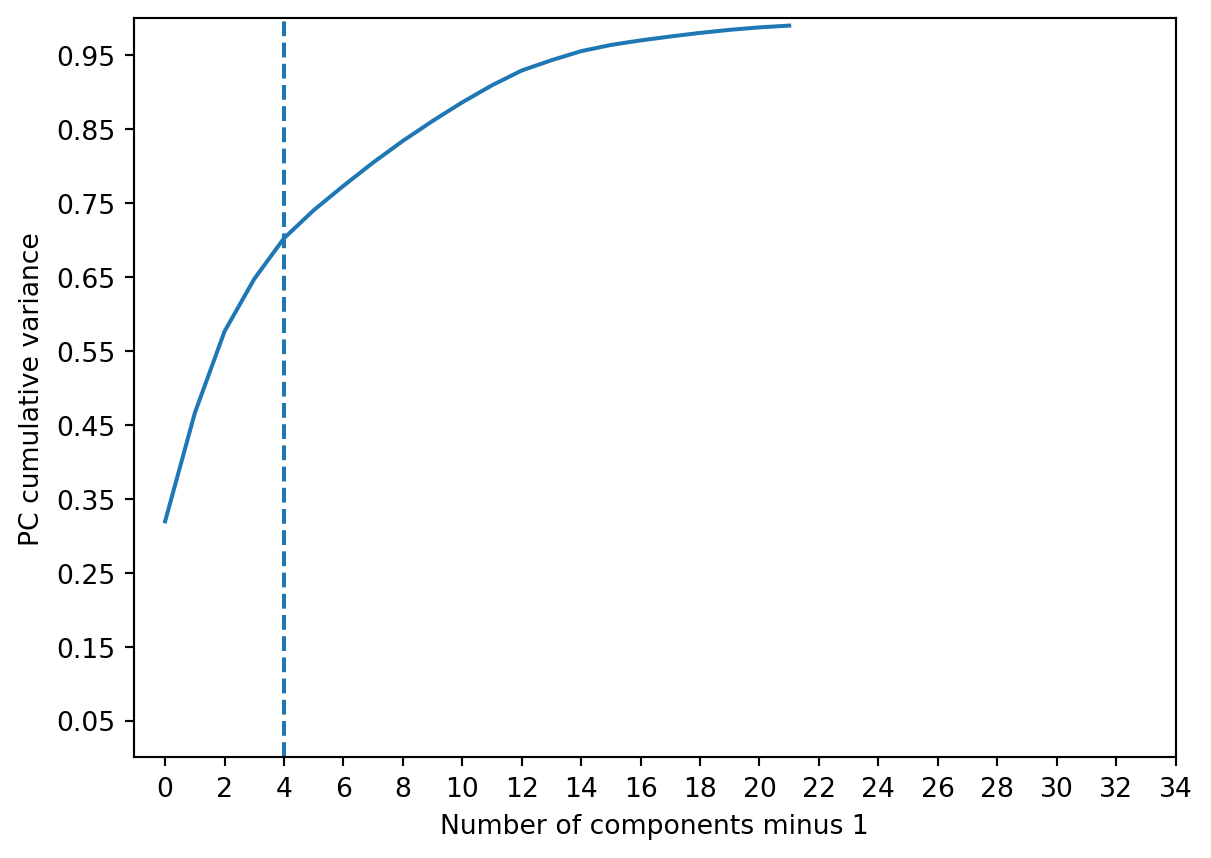
data.head()| RECORD | BBLE | BORO | BLOCK | LOT | EASEMENT | OWNER | BLDGCL | TAXCLASS | LTFRONT | ... | BLDFRONT | BLDDEPTH | AVLAND2 | AVTOT2 | EXLAND2 | EXTOT2 | EXCD2 | PERIOD | YEAR | VALTYPE | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 1000010101 | 1 | 1 | 101 | NaN | U S GOVT LAND & BLDGS | P7 | 4 | 500 | ... | 0 | 0 | 3775500.0 | 8613000.0 | 3775500.0 | 8613000.0 | NaN | FINAL | 2010/11 | AC-TR |
| 1 | 2 | 1000010201 | 1 | 1 | 201 | NaN | U S GOVT LAND & BLDGS | Z9 | 4 | 27 | ... | 0 | 0 | 11111400.0 | 80690400.0 | 11111400.0 | 80690400.0 | NaN | FINAL | 2010/11 | AC-TR |
| 2 | 3 | 1000020001 | 1 | 2 | 1 | NaN | DEPT OF GENERAL SERVI | Y7 | 4 | 709 | ... | 709 | 564 | 32321790.0 | 40179510.0 | 32321790.0 | 40179510.0 | NaN | FINAL | 2010/11 | AC-TR |
| 3 | 4 | 1000020023 | 1 | 2 | 23 | NaN | DEPARTMENT OF BUSINES | T2 | 4 | 793 | ... | 85 | 551 | 13644000.0 | 15750000.0 | 13644000.0 | 15750000.0 | NaN | FINAL | 2010/11 | AC-TR |
| 4 | 5 | 1000030001 | 1 | 3 | 1 | NaN | PARKS AND RECREATION | Q1 | 4 | 323 | ... | 89 | 57 | 106348680.0 | 107758350.0 | 106348680.0 | 107758350.0 | NaN | FINAL | 2010/11 | AC-TR |
5 rows × 32 columns